
At AWS, we don't mark many anniversaries. But every year when March 14th comes around, it's a good reminder that Amazon S3 originally launched on Pi Day, March 14, 2006. The Amazon S3 team still celebrate with homemade pies!
March 26, 2008 doesn't have any delicious desserts associated with it, but that's the day when we launched Availability Zones for Amazon EC2. A concept that has changed infrastructure architecture is now at the core of both AWS and customer reliability and operations.
Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them. Each data center is highly reliable, and has redundant power, including UPS and generators. Even though the network design for each data center is massively redundant, interruptions can still occur.
Availability Zones draw a hard line around the scope and magnitude of those interruptions. No two zones are allowed to share low-level core dependencies, such as power supply or a core network. Different zones can't even be in the same building, although sometimes they are large enough that a single zone spans several buildings.
We launched with three autonomous Availability Zones in our US East (N. Virginia) Region. By using zones, and failover mechanisms such as Elastic IP addresses and Elastic Load Balancing, you can provision your infrastructure with redundancy in mind. When two instances are in different zones, and one suffers from a low-level interruption, the other instance should be unaffected.
How Availability Zones have changed over the years
Availability Zones were originally designed for physical redundancy, but over time they have become re-used for more and more purposes. Zones impact how we build, deploy, and operate software, as well as how we enforce security controls between our largest systems.
For example, many AWS services are now built so that as much functionality as possible can be autonomous within an Availability Zone. The calls used to launch and manage EC2 instances, fail over an RDS instance, or handle the health of instances behind a load balancer, all work within one zone.
This design has a double benefit. First, if an Availability Zone does lose power or connectivity, the remaining zones are unaffected. The second benefit is even more powerful: if there is an error in the software, the risk of that error affecting other zones is minimized.

We maximize this benefit when we deploy new versions of our software, or operational changes such as a configuration edit, as we often do so zone-by-zone, one zone in a Region at a time. Although we automate, and don't manage instances by hand, our developers and operators know not to build tools or procedures that could impact multiple Availability Zones. I'd wager that every new AWS engineer knows within their first week, if not their first day, that we never want to touch more than one zone at a time.
Availability Zones run deep in our AWS development and operations culture, at every level. AWS customers can think of zones in terms of redundancy, "Use two or more Availability Zones for reliability." At AWS, we think of zones in terms of isolation, "Stay within the Availability Zone, as much as possible."
Silo your traffic or not – you choose
When your architecture does stay within an Availability Zone as much as possible, there are more benefits. One is that the latency within a zone is incredibly fast. Today, packets between EC2 instances in the same zone take just tens of microseconds to reach other.
Another benefit is that redundant zonal architectures are easier to recover from complex issues and emergent behaviors. If all of the calls between the various layers of a service stay within one Availability Zone, then when issues occur they can quickly be remediated by removing the entire zone from service, without needing to identify the layer or component that was the trigger.

Many of you also use this kind of "silo" pattern in your own architecture, where Amazon Route 53 or Elastic Load Balancing can be used to choose an Availability Zone to handle a request, but can also be used to keep subsequent internal requests and dependencies within that same zone. This is only meaningful because of the strong boundaries and separation between zones at the AWS level.
Regional isolation
Not too long after we launched Availability Zones, we also launched our second Region, EU (Ireland). Early in the design, we considered operating a seamless global network, with open connectivity between instances in each Region. Services such as S3 would have behaved as "one big S3," with keys and data accessible and mutable from either location.
The more we thought through this design, the more we realized that there would be risks of issues and errors spreading between Regions, potentially resulting in large-scale interruptions that would defeat our most important goals:
- To provide the highest levels of availability
- To allow Regions to act as standby sites for each other
- To provide geographic diversity and lower latencies to end users
Our experience with the benefits of Availability Zones meant that instead we doubled down on compartmentalization, and decided to isolate Regions from each other with our hardest boundaries. Since then, and still today, our services operate autonomously in each Region, full stacks of S3, DynamoDB, Amazon RDS, and everything else.

Many of you still want to be able to run workloads and access data globally. For our edge services such as Amazon CloudFront, Amazon Route 53, and AWS Lambda@Edge, we operate over 100 points of presence. Each is its own Availability Zone with its own compartmentalization.
As we develop and ship our services that span Regions, such as S3 cross-region object replication, Amazon DynamoDB global tables, and Amazon VPC inter-region peering, we take enormous care to ensure that the dependencies and calling patterns between Regions are asynchronous and ring-fenced with high-level safety mechanisms that prevent errors from spreading.
Doubling down on compartmentalization, again
With the phenomenal growth of AWS, it can be humbling how many customers are being served even by our smallest Availability Zones. For some time now, many of our services have been operating service stacks that are compartmentalized even within zones.
For example, AWS HyperPlane—the internal service that powers NAT gateways, Network Load Balancers, and AWS PrivateLink—is internally subdivided into cells that each handle a distinct set of customers. If there are any issues with a cell, the impact is limited not just to an Availability Zone, but to a subset of customers within that zone. Of course, all sorts of automation immediately kick in to mitigate any impact to even that subset.
Ten years after launching Availability Zones, we're excited that we're still relentless about reducing the impact of potential issues. We firmly believe it's one of the most important strategies for achieving our top goals of security and availability. We now have 54 Availability Zones, across 18 geographic Regions, and we've announced plans for 12 more. Beyond that geographic growth, we'll be extending the concept of compartmentalization that underlies Availability Zones deeper and deeper, to be more effective than ever.

In machine learning, more is usually more. For example, training on more data means more accurate models.
At AWS, we continue to strive to enable builders to build cutting-edge technologies faster in a secure, reliable, and scalable fashion. Machine learning is one such transformational technology that is top of mind not only for CIOs and CEOs, but also developers and data scientists. Last re:Invent, to make the problem of authoring, training, and hosting ML models easier, faster, and more reliable, we launched Amazon SageMaker. Now, thousands of customers are trying Amazon SageMaker and building ML models on top of their data lakes in AWS.
While building Amazon SageMaker and applying it for large-scale machine learning problems, we realized that scalability is one of the key aspects that we need to focus on. So, when designing Amazon SageMaker we took on a challenge: to build machine learning algorithms that can handle an infinite amount of data. What does that even mean though? Clearly, no customer has an infinite amount of data.
Nevertheless, for many customers, the amount of data that they have is indistinguishable from infinite. Bill Simmons, CTO of Dataxu, states, "We process 3 million ad requests a second - 100,000 features per request. That's 250 trillion ad requests per day. Not your run-of-the-mill data science problem!" For these customers and many more, the notion of "the data" does not exist. It's not static. Data always keeps being accrued. Their answer to the question "how much data do you have?" is "how much can you handle?"
To make things even more challenging, a system that can handle a single large training job is not nearly good enough if training jobs are slow or expensive. Machine learning models are usually trained tens or hundreds of times. During development, many different versions of the eventual training job are run. Then, to choose the best hyperparameters, many training jobs are run simultaneously with slightly different configurations. Finally, re-training is performed every x-many minutes/hours/days to keep the models updated with new data. In fraud or abuse prevention applications, models often need to react to new patterns in minutes or even seconds!
To that end, Amazon SageMaker offers algorithms that train on indistinguishable-from-infinite amounts of data both quickly and cheaply. This sounds like a pipe dream. Nevertheless, this is exactly what we set out to do. This post lifts the veil on some of the scientific, system design, and engineering decisions we made along the way.
Streaming algorithms
To handle unbounded amounts of data, our algorithms adopt a streaming computational model. In the streaming model, the algorithm only passes over the dataset one time and assumes a fixed-memory footprint. This memory restriction precludes basic operations like storing the data in memory, random access to individual records, shuffling the data, reading through the data several times, etc.
Streaming algorithms are infinitely scalable in the sense that they can consume any amount of data. The cost of adding more data points is independent of the entire corpus size. In other words, processing the 10th gigabyte and 1000th gigabyte is conceptually the same. The memory footprint of the algorithms is fixed and it is therefore guaranteed not to run out of memory (and crash) as the data grows. The compute cost and training time depend linearly on the data size. Training on twice as much data costs twice as much and take twice as long.
Finally, traditional machine learning algorithms usually consume data from persistent data sources such as local disk, Amazon S3, or Amazon EBS. Streaming algorithms also natively consume ephemeral data sources such as Amazon Kinesis streams, pipes, database query results, and almost any other data source.
Another significant advantage of streaming algorithms is the notion of a state. The algorithm state contains all the variables, statistics, and data structures needed to perform updates, that is, all that is required to continue training. By formalizing this concept and facilitating it with software abstractions, we provide checkpointing capabilities and fault resiliency for all algorithms. Moreover, checkpointing enables multi-pass/multi-epoch training for persistent data, a pause/resume mechanism that is useful for cost effective HPO, and incremental training that updates the model only with new data rather running the entire training job from scratch.
Acceleration and distribution
When AWS customers run large-scale training tasks on Amazon SageMaker, they are interested in reducing the running time and cost of their job, irrespective of the number and kinds of machines used under the hood. Amazon SageMaker algorithms are therefore built to take advantage of many Amazon EC2 instance types, support both CPU and GPU computation, and distribute across many machines.
Cross-instance support relies heavily on containerization. Amazon SageMaker training supports powerful container management mechanisms that include spinning up large numbers of containers on different hardware with fast networking and access to the underlying hardware, such as GPUs. For example, a training job that takes ten hours to run on a single machine can be run on 10 machines and conclude in one hour. Furthermore, switching those machines to GPU-enabled ones could reduce the running time to minutes. This can all be done without touching a single line of code.
To seamlessly switch between CPU and GPU machines, we use Apache MXNet to interface with the underlying hardware. By designing algorithms that operate efficiently on different types of hardware, our algorithms gain record speeds and efficiency.
Distribution across machines is achieved via a parameter server that stores the state of all the machines participating in training. The parameter server is designed for maximal throughput by updating parameters asynchronously and offering only loose consistency properties of the parameters. While these are unacceptable in typical relational database designs, for machine learning, the tradeoff between accuracy and speed is worth it.
Post-training model tuning and rich states
Processing massively scalable datasets in a streaming manner poses a challenge for model tuning, also known as hyperparameter optimization (HPO). In HPO, many training jobs are run with different configurations or training parameters. The goal is to find the best configuration, usually the one corresponding to the best test accuracy. This is impossible in the streaming setting.
For ephemeral data sources, the data is no longer available for rerunning the training job (for persistent data sources, this is possible but inefficient). Amazon SageMaker algorithms solve this by training an expressive state object, out of which many different models can be created. That is, a large number of different training configurations can be explored after only a single training job.
Summary
Amazon SageMaker offers production-ready, infinitely scalable algorithms such as:
- Linear Learner
- Factorization Machines
- Neural Topic Modeling
- Principal Component Analysis (PCA)
- K-Means clustering
- DeepAR forecasting
They adhere to the design principles above and rely on Amazon SageMaker's robust training stack. They are operationalized by a thick, common SDK that allows us to test them thoroughly before deployment. We have invested heavily in the research and development of each algorithm, and every one of them advances the state of the art. Amazon SageMaker algorithms train larger models on more data than any other open-source solution out there. When a comparison is possible, Amazon SageMaker algorithms often run more than 10x faster than other ML solutions like Spark ML. Amazon SageMaker algorithms often cost cents on the dollar to train, in terms of compute costs, and produce more accurate models than the alternatives.
I think the time is here for using large-scale machine learning in large-scale production systems. Companies with truly massive and ever-growing datasets must not fear the overhead of operating large ML systems or developing the associated ML know-how. AWS is delighted to innovate on our customers' behalf and to be a thought leader, especially in exciting areas like machine learning. I hope and believe that Amazon SageMaker and its growing set of algorithms will change the way companies do machine learning.

At Amazon, we are heavily invested in machine learning (ML), and are developing new tools to help developers quickly and easily build, train, and deploy ML models. The power of ML is in its ability to unlock a new set of capabilities that create value for consumers and businesses. A great example of this is the way we are using ML to deal with one of the world's biggest and most tangled datasets: human speech.
Voice-driven conversation has always been the most natural way for us to communicate. Conversations are personal and they convey context, which helps us to understand each other. Conversations continue over time, and develop history, which in turn builds richer context. The challenge was that technology wasn't capable of processing real human conversation.
The interfaces to our digital system have been dictated by the capabilities of our computer systems—keyboards, mice, graphical interfaces, remotes, and touch screens. Touch made things easier; it let us tap on screens to get the app that we wanted. But what if touch isn't possible or practical? Even when it is, the proliferation of apps has created a sort of "app fatigue". This essentially forces us to hunt for the app that we need, and often results in us not using many of the apps that we already have. None of these approaches are particularly natural. As a result, they fail to deliver a truly seamless and customer-centric experience that integrates our digital systems into our analog lives.
Voice becomes a game changer
Using your voice is powerful because it's spontaneous, intuitive, and enables you to interact with technology in the most natural way possible. It may well be considered the universal user interface. When you use your voice, you don't need to adapt and learn a new user interface. Voice interfaces don't need to be application-centric, so you don't have to find an app to accomplish the task that you want. All of these benefits make voice a game changer for interacting with all kinds of digital systems.
Until 2-3 years ago we did not have the capabilities to process voice at scale and in real time. The availability of large scale voice training data, the advances made in software with processing engines such as Caffe, MXNet and Tensflow, and the rise of massively parallel compute engines with low-latency memory access, such as the Amazon EC2 P3 instances have made voice processing at scale a reality.
Today, the power of voice is most commonly used in the home or in cars to do things like play music, shop, control smart home features, and get directions. A variety of digital assistants are playing a big role here. When we released Amazon Alexa, our intelligent, cloud-based voice service, we built its voice technology on the AWS Natural Language Processing platform powered by ML algorithms. Alexa is constantly learning, and she has tens of thousands of skills that extend beyond the consumer space. But by using the stickiness of voice, we think there are even more scenarios that can be unlocked at work.
Helping more people and organizations use voice
People interact with many different applications and systems at work. So why aren't voice interfaces being used to enable these scenarios? One impediment is the ability to manage voice-controlled interactions and devices at scale, and we are working to address this with Alexa for Business. Alexa for Business helps companies voice-enable their spaces, corporate applications, people, and customers.
To use voice in the workplace, you really need three things. The first is a management layer, which is where Alexa for Business plays. Second, you need a set of APIs to integrate with your IT apps and infrastructure, and third is having voice-enabled devices everywhere.
Voice interfaces are a paradigm shift, and we've worked to remove the heavy lifting associated with integrating Alexa voice capabilities into more devices. For example, Alexa Voice Service (AVS), a cloud-based service that provides APIs to interface with Alexa, enables products built using AVS to have access to Alexa capabilities and skills.
We're also making it easy to build skills for the things you want to do. This is where the Alexa Skills Kit and the Alexa Skills Store can help both companies and developers. Some organizations may want to control who has access to the skills that they build. In those cases, Alexa for Business allows people to create a private skill that can only be accessed by employees in your organization. In just a few months, our customers have built hundreds of private skills that help voice-enabled employees do everything from getting internal news briefings to asking what time their help desk closes.
Voice-enabled spaces
Just like Alexa is making smart homes easier, the same is possible in the workplace. Alexa can control the environment, help you find directions, book a room, report an issue, or find transportation. One of the biggest applications of voice in the enterprise is conference rooms and we've built some special skills in this area to allow people to be more productive.
For example, many meetings fail to start on time. It's usually a struggle to find the dial-in information, punch in the numbers, and enter a passcode every time a meeting starts. With Alexa for Business, the administrator can configure the conference rooms and integrate calendars to the devices. When you walk into a meeting, all you have to say is "Alexa, start my meeting". Alexa for Business automatically knows what the meeting is from the integrated calendar, mines the dial-in information, dials into the conference provider, and starts the meeting. Furthermore, you can also configure Alexa for Business to automatically lower the projector screen, dim the lights, and more. People who work from home can also take advantage of these capabilities. By using Amazon Echo in their home office and asking Alexa to start the meeting, employees who have Alexa for Business in their workplace are automatically connected to the meeting on their calendar.
Voice-enabled applications
Voice interfaces will really hit their stride when we begin to see more voice-enabled applications. Today, Alexa can interact with many corporate applications including Salesforce, Concur, ServiceNow, and more. IT developers who want to take advantage of voice interfaces can enable their custom apps using the Alexa Skills Kit, and make their skills available just for their organization. There are a number of agencies and SIs that can help with this, and there are code repositories with code examples for AWS services.
We're seeing a lot of interesting use cases with Alexa for Business from a wide range of companies. Take WeWork, a provider of shared workspaces and services. WeWork has adopted Alexa, managed by Alexa for Business, in their everyday workflow. They have built private skills for Alexa that employees can use to reserve conference rooms, file help tickets for their community management team, and get important information on the status of meeting rooms. Alexa for Business makes it easy for WeWork to configure and deploy Alexa-enabled devices, and the Alexa skills that they need to improve their employees' productivity.
The next generation of corporate systems and applications will be built using conversational interfaces, and we're beginning to see this happen with customers using Alexa for Business in their workplace. Want to learn more? If you are attending Enterprise Connect in Orlando next week, I encourage you to attend the AWS keynote on March 13 given by Collin Davis. Collin's team has focused on helping customers use voice to manage everyday tasks. He'll have more to share about the advances we're seeing in this space, and what we're doing to help our customers be successful in a voice-enabled era.
When it comes to enabling voice capabilities at home and in the workplace, we're here to help you build.
This article titled "Daten müssen strategischer Teil des Geschäfts werden" appeared in German last week in the "IT und Datenproduktion" column of Wirtschaftwoche.

How companies can use ideas from mass production to create business with data
Strategically, IT doesn't matter. That was the provocative thesis of a much-talked-about article from 2003 in the Harvard Business Review by the US publicist Nicolas Carr. Back then, companies spent more than half of their entire investment for their IT, in a non-differentiating way. In a world in which tools are equally accessible for every company, they wouldn't offer any competitive advantage – so went the argument. The author recommended steering investments toward strategically relevant resources instead. In the years that followed, many companies outsourced their IT activities because they no longer regarded them as being part of the core business.
A new age
Nearly 15 years later, the situation has changed. In today's era of global digitalization there are many examples that show that IT does matter. Developments like cloud computing, the internet of things, artificial intelligence, and machine learning are proving that IT has (again) become a strategic business driver. This is transforming the way companies offer products and services to their customers today. Take the example of industrial manufacturing: in prototyping, drafts for technologically complex products are no longer physically produced; rather, their characteristics can be tested in a purely virtual fashion at every location across the globe by using simulations. The German startup SimScale makes use of this trend. The founders had noticed that in many companies, product designers worked in a very detached manner from the rest of production. The SimScale platform can be accessed through a normal web browser. In this way, designers are part of an ecosystem in which the functionalities of simulations, data and people come together, enabling them to develop better products faster.
Value-added services are also playing an increasingly important role for both companies and their customers. For example, Kärcher, the maker of cleaning technologies, manages its entire fleet through the cloud solution "Kärcher Fleet". This transmits data from the company's cleaning devices e.g. about the status of maintenance and loading, when the machines are used, and where the machines are located. The benefit for customers: Authorized users can view this data and therefore manage their inventories across different sites, making the maintenance processes much more efficient.
Kärcher benefits as well: By developing this service, the company gets exact insight into how the machines are actually used by its customers. By knowing this, Kärcher can generate new top-line revenue in the form of subscription models for its analysis portal.
More than mere support
These examples underline that the purpose of software today is not solely to support business processes, but that software solutions have broadly become an essential element in multiple business areas. This starts with integrated platforms that can manage all activities, from market research to production to logistics. Today, IT is the foundation of digital business models, and therefore has a value-added role in and of itself. That can be seen when sales people, for example, interact with their customers in online shops or via mobile apps. Marketers use big data and artificial intelligence to find out more about the future needs of their customers. Breuninger, a fashion department store chain steeped in tradition, has recognized this and relies on a self-developed e-commerce platform in the AWS Cloud. Breuninger uses modern templates for software development, such as Self-Contained Systems (SCS), so that it can increase the speed of software development with agile and autonomous teams and quickly test new features. Each team acts according to the principle: "You build it, you run it". Hence, the teams are themselves responsible for the productive operation of the software. The advantage of this approach is that when designing new applications, there is already a focus on the operating aspects.
Value creation through data
In a digital economy, data are at the core of value creation, whereas physical assets are losing their significance in business models. Until 1992, the most highly valued companies in the S&P 500 Index were those that made or distributed things (for example the pharmaceutical industry, trade). Today, developers of technology (for example medical technology, software) and platform operators (social media enablers, credit card companies) are at the top. Also, trade with data contributes more to global growth than trade with goods. Therefore, IT has never been more important for strategy than it is now – not only for us, but for every company in the digital age. Anyone who wants to further develop his business digitally can't do that today without at the same time thinking about which IT infrastructure, which software and which algorithms he needs in order to achieve his plans.
If data take center stage then companies must learn how to create added value out of it – namely by combining the data they own with external data sources and by using modern, automated analytics processes. This is done through software and IT services that are delivered through software APIs.
Companies that want to become successful and innovative digital players need to get better at building software solutions.We should ponder how we can organize the 'production' of data in such a way so that we ultimately come out with a competitive advantage. We need mechanisms that enable the mass production of data using software and hardware capabilities. These mechanisms need to be lean, seamless and effective. At the same time, we need to ensure that quality requirements can be met. Those are exactly the challenges that were solved for physical goods through the industrialization of manufacturing processes. A company that wants to industrialize 'software production' needs to find ideas on how to achieve the same kind of lean and qualitatively first-class mass production that has already occurred for industrial goods. And inevitably, the first place to look will be lean production approaches such as Kanban and Kaizen, or total quality management. In the 1980s, companies like Toyota revolutionized the production process by reengineering the entire organization and focusing the company on similar principles. Creating those conditions, both from an organizational and IT- standpoint, is one of the biggest challenges that companies face in the digital age.
Learn from lean
Can we transfer this success model to IT as well? The answer is yes. In the digital world, it is decisive to activate data-centric processes and continuously improve them. Thus, any obstacles that stand in the way of experimentation and the further development of new ideas should be removed as fast as possible. Every new IT project should be regarded as an idea that must go through a data factory – a fully equipped production site with common processes that can be easily maintained. The end-product is high-quality services or algorithms that support digital business models. Digital companies differentiate themselves through their ideas, data and customer relationships. Those that find a functioning digital business model the fastest will have a competitive edge. Above all, the barrier between software development and the operating business has to be overcome. The reason is that the success and speed and frequency of these experiments depend on the performance of IT development, and at the same time on the relevance of the solutions for business operations. Autoscout24 has gained an enormous amount of agility through its cloud solution. The company meanwhile has 15 autonomous interdisciplinary teams working constantly to test and explore new services. The main goal in all this is to have the possibility to quickly iterate experiments through the widest range of architectures, combine services with each other, and compare approaches.
In order to become as agile as Autoscout24, companies need a "machine" that produces ideas. Why not transfer the success formulas from industrial manufacturing and the principles of quality management to the creation of software?
German industrial companies in particular possess a manufacturing excellence that has been built up over many decades. Where applicable, they should do their best to transfer this knowledge to their IT, and in particular to their software development.
In many companies, internal IT knowhow has not developed fast enough in the last few years – quite contrary to the technological possibilities. Customers provide feedback online immediately after their purchase. Real-time analyses are possible through big data and software updates are generated daily through the cloud. Often, the IT organization and its associated processes couldn't keep up. As a consequence, specialist departments with the structures of yesterday are supposed to fulfill customer requirements of tomorrow. Bringing innovative products and services quickly to market is not possible with long-term IT sourcing cycles. It's no wonder that many of specialist departments try to circumvent their own IT department, for example by shifting activities to the cloud, which offers many powerful IT building blocks through easy-to-use APIs for which companies previously had to operate complicated software and infrastructure. Such a decentralized 'shadow IT' delivers no improvements. The end effect is that the complexity of the system increases, which is not efficient. This pattern should be broken. Development and Operations need to work hand in hand instead of working sequentially after each other, as in the old world. And ideally, this should be done in many projects running parallel. Under the heading of DevOps – the combination of "Development and Operations" – IT guru Gene Kim has described the core characteristics of this machinery.
Ensuring the flow
Kim argues that theorganization must be built around the customer benefit and that the flow of projects must be as smooth as possible. Hurdles that block the creation of client benefits should be identified and removed. At Amazon this starts by staffing projects with cross-functional and interdisciplinary teams as a rule. Furthermore, for the sake of agility the teams should not exceed a certain size. We have a rule that teams should be exactly the size that allows everyone to feel full after eating two (large!) pizzas. This approach reduces the number of necessary handovers, increases responsibility, and allows the team to provide customers with software faster.
Incorporating feedback
The earlier client feedback flows back into the "production process", the better. In addition, companies must ensure that every piece of feedback is applied to future projects. To avoid getting lost in endless feedback loops, this should be organized in a lean way: Obtaining the feedback of internal and external stakeholders must by no means hamper the development process.
Learning to take risks
"Good intentions never work, you need good mechanisms to make anything happen," says Jeff Bezos. For that, you need a corporate culture that teaches employees to experiment constantly and deliver. With every new experiment, one should risk yet another small step forward behind the previous step. At the same time, from every team we need data based on predefined KPIs about the impact of the experiments. And we need to establish mechanisms that take effect immediately if we go too far or if something goes wrong, for example if the solution never reached the customer.
Anyone who has tried this knows it's not easy to start your own digital revolution in the company and keep the momentum going. P3 advises cellular operators and offers its customers access to data that provide information about the quality of cellular networks (for example signal strength, broken connection and the data throughput) – worldwide and independent of the network operator and cellular provider. This allows the customers to come up with measures in order to expand their networks or new offerings for a more efficient utilization of their capacity. By introducing DevOps tools, P3 can define an automated process that implements the required compute infrastructure in the AWS Cloud and deploys project-specific software packages with the push of a button. Moreover, the process definition can be revised by developers, the business or data scientists at any time, for example in order to develop new regions, add analytics software or implement new AWS services. Now P3 can focus fully on its core competence, namely developing its proprietary software. Data scientists can use their freed-up resources to analyze in real time data that are collected from around the world and put insights from the analysis at the disposal of their clients
The cloud offers IT limitless possibilities on the technical side, from which new opportunities have been born. But it's becoming ever clearer what is required in order to make use of these opportunities. Technologies change faster than people. And individuals faster than entire organizations. Tackling these challenges is a strategic necessity. Changing the organization is the next bottleneck on the way to becoming a digital champion.

Today, I'm happy to announce that the AWS EU (Paris) Region, our 18th technology infrastructure Region globally, is now generally available for use by customers worldwide. With this launch, AWS now provides 49 Availability Zones, with another 12 Availability Zones and four Regions in Bahrain, Hong Kong, Sweden, and a second AWS GovCloud (US) Region expected to come online by early 2019.
In France, you can find one of the most vibrant startup ecosystems in the world, a strong research community, excellent energy, telecom, and transportation infrastructure, a very strong agriculture and food industry, and some of the most influential luxury brands in the world. The cloud is an opportunity to stay competitive in each of these domains by giving companies freedom to innovate quickly. This is why tens of thousands of French customers already use AWS in Regions around the world. Starting today, developers, startups, and enterprises, as well as government, education, and non-profit organizations can leverage AWS to run applications and store data in France.
French companies are using AWS to innovate in a secure way across industries as diverse as energy, financial services, manufacturing, media, pharmaceuticals and health sciences, retail, and more. Companies of all sizes across France are also using AWS to innovate and grow, from startups like AlloResto, CaptainDash, Datadome, Drivy, Predicsis, Payplug, and Silkke to enterprises like Decathlon, Nexity, Soitec, TF1 as well as more than 80 percent of companies listed on the CAC 40, like Schneider Electric, Societe Generale, and Veolia.
We are also seeing a strong adoption of AWS within the public sector with organizations using AWS to transform the services they deliver to the citizens of France.Kartable, Les Restos du Coeur, OpenClassrooms, Radio France, SNCF, and many more are using AWS to lower costs and speed up their rate of experimentation so they can deliver reliable, secure, and innovative services to people across the country.
The opening of the AWS EU (Paris) Region adds to our continued investment in France. Over the last 11 years, AWS has expanded its physical presence in the country, opening an office in La Defense and launching Edge Network Locations in Paris and Marseille. Now, we're opening an infrastructure Region with three Availability Zones. We decided to locate the AWS data centers in the area of Paris, the capital and economic center of France because it is home to many of the world's largest companies, the majority of the French public sector, and some of Europe's most dynamic startups.
To give customers the best experience when connecting to the new Region, today we are also announcing the availability of AWS Direct Connect. Today, customers can connect to the AWS EU (Paris) Region via Telehouse Voltaire. In January 2018, customers will be able to connect via Equinix Paris in January and later in the year via Interxion Paris. Customers that have equipment within these facilities can use Direct Connect to optimize their connection to AWS.
In addition to physical investments, we have also continually invested in people in France. For many years, we have been growing teams of account managers, solutions architects, trainers, business development, and professional services specialists, as well as other job functions. These teams are helping customers and partners of all sizes, including systems integrators and ISVs, to move to the cloud.
We have also been investing in helping to grow the entire French IT community with training, education, and certification programs. To continue this trend, we recently announced plans for AWS to train, at no charge, more than 25,000 people in France, helping them to develop highly sought-after skills. These people will be granted access to AWS training resources in France via existing programs such as AWS Academy, AWS Educate, AWSome days. They also get access to webinars delivered in French by AWS Technical Trainers and AWS Certified Trainers. To learn more about these trainings or discover when the next event will take place, visit: https://aws.amazon.com/fr/events/
All around us, we see AWS technologies fostering a culture of experimentation. I have been humbled by how much our French customers have been able to achieve using AWS technology. Over the past few months we've had Engie and Radio France at the AWS Summit, as well as Decathlon, Smatis, Soitec and Veolia at the AWS Transformation Days in Lille, Lyon, Nantes, Paris, and Toulouse. Everyone was talking about how they are using AWS to transform and scale their organizations. I, for one, look forward to seeing many more innovative use cases enabled by the cloud at the next AWS Summit in France!
Our AWS EU (Paris) Region is open for business now. We are excited to offer a complete portfolio of services, from our foundational technologies, such as compute, storage, and networking, to our more advanced solutions and applications such as artificial intelligence, IoT, machine learning, and serverless computing. We look forward to continuing to broaden this portfolio to include more services into the future. For more information about the new AWS EU (Paris) Region, or to get started now, I would encourage you to visit: https://aws.amazon.com/fr/paris/.

Today, I am happy to announce the general availability of AWS China (Ningxia) Region, operated by Ningxia Western Cloud Data Technology Co. Ltd. (NWCD). This is our 17th Region globally, and the second in China. To comply with China's legal and regulatory requirements, AWS has formed a strategic technology collaboration with NWCD to operate and provide services from the AWS China (Ningxia) Region. Founded in 2015, NWCD is a licensed data center and cloud services provider, based in Ningxia, China.
Coupled with the AWS China (Beijing) Region operated by Sinnet, the AWS China (Ningxia) Region, operated by NWCD, serves as the foundation for new cloud initiatives in China, especially in Western China. Both Regions are helping to transform businesses, increase innovation, and enhance the regional economy.
Thousands of customers in China are already using AWS services operated by Sinnet, to innovate in diverse areas such as energy, education, manufacturing, home security, mobile and internet platforms, CRM solutions, and the dairy industry, among others. These customers include large Chinese enterprises such as Envision Energy, Xiaomi, Lenovo, OPPO, TCL, Hisense, Mango TV, and Mengniu; well-known, fast growing startups including iQiyi, VIPKID, musical.ly, Xiaohongshu, Meitu, and Kunlun; and multinationals such as Samsung, Adobe, ThermoFisher Scientific, Dassault Systemes, Mapbox, Glu, and Ayla Networks. With AWS, Chinese customers can leverage world-class technologies both within China and around the world.
As this breadth of customers shows, we believe that AWS can and will serve China's innovation agenda. We are excited to collaborate with NWCD in Ningxia and Sinnet in Beijing to offer a robust portfolio of services. Our offerings range from our foundational service stack for compute, storage, and networking to our more advanced solutions and applications.
Starting today, China-based developers, startups, and enterprises, as well as government, education, and non-profit organizations, can use AWS to run their applications and store their data in the new AWS China (Ningxia) Region, operated by NWCD. Customers already using the AWS China (Beijing) Region, operated by Sinnet, can select the AWS China (Ningxia) Region directly from the AWS Management Console. New customers can request an account at www.amazonaws.cnto begin using both AWS China Regions.

Applications based on machine learning (ML) can provide tremendous business value. However, many developers find them difficult to build and deploy. As there are few individuals with this expertise, an easier process presents a significant opportunity for companies who want to accelerate their ML usage.
Though the AWS Cloud gives you access to the storage and processing power required for ML, the process for building, training, and deploying ML models has unique challenges that often block successful use of this powerful new technology.
The challenges begin with collecting, cleaning, and formatting training data. After the dataset is created, you must scale the processing to handle the data, which can often be a blocker. After this, there is often a long process of training that includes tuning the knobs and levers, called hyperparameters, that control the different aspects of the training algorithm. Finally, figuring out how to move the model into a scalable production environment can often be slow and inefficient for those that do not do it routinely.
At Amazon Web Services, we've committed to helping you unlock the value of your data through ML, through a set of supporting tools and resources that improve the ML model development experience. From the Deep Learning AMI and the distributed Deep Learning AWS CloudFormation template, to Gluon in Apache MXNet, we've focused on improvements that remove the roadblocks to development.
We also recently announced the Amazon ML Solutions Lab, which is a program to help you accelerate your use of ML in products and processes. As the adoption of these technologies continues to grow, customers have demanded a managed service for ML, to make it easier to get started.
Today, we are announcing the general availability of Amazon SageMaker. This new managed service enables data scientists and developers to quickly and easily build, train, and deploy ML models without getting mired in the challenges that slow this process down today.
Amazon SageMaker provides the following features:
- Hosted Jupyter notebooks that require no setup, so that you can start processing your training dataset and developing your algorithms immediately.
- One-click, on-demand distributed training that sets up and tears down the cluster after training.
- Built-in, high-performance ML algorithms, re-engineered for greater, speed, accuracy, and data-throughput.
- Built-in model tuning (hyperparameter optimization) that can automatically adjust hundreds of different combinations of algorithm parameters.
- An elastic, secure, and scalable environment to host your models, with one-click deployment.
In the hosted notebook environment, Amazon SageMaker takes care of establishing secure network connections in your VPC and launching an ML instance. This development workspace also comes pre-loaded with the necessary Python libraries and CUDA drivers, attaches an Amazon EBS volume to automatically persist notebook files, and installs TensorFlow, Apache MXNet, and Keras deep learning frameworks. Amazon SageMaker also includes common examples to help you get started quickly.
For training, you simply indicate the type and quantity of ML instances you need and initiate training with a single click. Amazon SageMaker then sets up the distributed compute cluster, installs the software, performs the training, and tears down the cluster when complete. You only pay for the resources that you use and never have to worry about the underlying infrastructure.
Amazon SageMaker also reduces the amount of time spent tuning models using built-in hyperparameter optimization. This technology automatically adjusts hundreds of different combinations of parameters, to quickly arrive at the best solution for your ML problem. With high-performance algorithms, distributed computing, managed infrastructure, and hyperparameter optimization, Amazon SageMaker drastically decreases the training time and overall cost of building production systems.
When you are ready to deploy, Amazon SageMaker offers an elastic, secure, and scalable environment to host your ML models, with one-click deployment. After training, Amazon SageMaker provides the model artifacts for deployment to EC2 or anywhere else. You then specify the type and number of ML instances. Amazon SageMaker takes care of launching the instances, deploying the model, and setting up the HTTPS endpoint for your application to achieve low latency / high throughput prediction.
In production, Amazon SageMaker manages the compute infrastructure to perform health checks, apply security patches, and conduct other routine maintenance, all with built-in Amazon CloudWatch monitoring and logging.
Before Amazon SageMaker, you were faced with a tradeoff between the flexibility to use different frameworks and the ease of use of a single platform. At AWS, we believe in giving choices, so Amazon SageMaker removes that problem. You can now use the tools of your choice, with a single environment for training and hosting ML models.
Amazon SageMaker provides a set of built-in algorithms for traditional ML. For deep learning, Amazon SageMaker provides you with the ability to submit MXNet or TensorFlow scripts, and use the distributed training environment to generate a deep learning model. If you use Apache Spark, you can use Amazon SageMaker's library to leverage the advantages of Amazon SageMaker from a familiar environment. You can even bring your own algorithms and frameworks, in Docker containers, and use Amazon SageMaker to manage the training and hosting environments. Just like in Amazon RDS, where we support multiple engines like MySQL, PostgreSQL, and Aurora, we support multiple frameworks in Amazon SageMaker.
Finally, one of the best aspects of Amazon SageMaker is its modular architecture. You can use any combination of its building, training, and hosting capabilities to fit your workflow. For instance, you may use the build and training capabilities to prepare a production-ready ML model, and then deploy the model to a device on the edge, such as AWS DeepLens. Or, you may use only its hosting capabilities to simplify the deployment of models that you've already trained elsewhere. The flexibility of Amazon SageMaker's architecture enables you to easily incorporate its benefits into your existing ML workflows in whatever combination is best.
Amazon SageMaker is available today to all customers, in US East (N. Virginia), US East (Ohio), US West (Oregon), and EU West (Ireland). Try Amazon SageMaker for free and get started today!
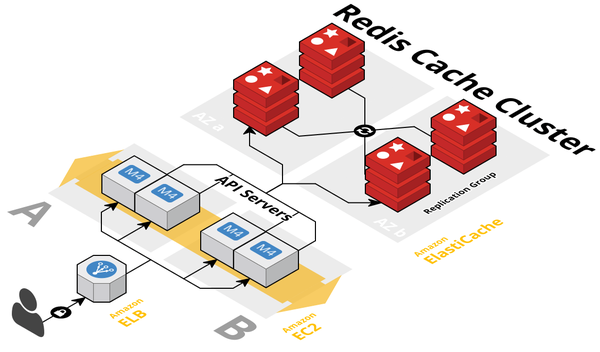
Amazon ElastiCache embodies much of what makes fast data a reality for customers looking to process high volume data at incredible rates, faster than traditional databases can manage. Developers love the performance, simplicity, and in-memory capabilities of Redis, making it among the most popular NoSQL key-value stores. Redis's microsecond latency has made it a de facto choice for caching. Its support for advanced data structures (for example, lists, sets, and sorted sets) also enables a variety of in-memory use cases such as leaderboards, in-memory analytics, messaging, and more.
Four years ago, as part of our AWS fast data journey, we introduced Amazon ElastiCache for Redis, a fully managed, in-memory data store that operates at microsecond latency. Since then, we have added support for Redis clusters, enabling customers to run faster and more scalable workloads. ElastiCache for Redis cluster configuration supports up to 15 shards and enables customers to run Redis workloads with up to 6.1 TB of in-memory capacity in a single cluster. While Redis cluster configuration enabled larger deployments with high performance, resizing the cluster required backup and restore, which meant taking the cluster offline.
Earlier this month, we announced online cluster resizing within ElastiCache. ElastiCache for Redis now provides the ability to add and remove shards from a running cluster. You can now dynamically scale out and even scale in your Redis cluster workloads to adapt to changes in demand. ElastiCache resizes the cluster by adding or removing shards and redistributing keys uniformly across the new shard configuration, all while the cluster continues to stay online and serve requests. No application changes are needed.
Scaling with elasticity
Having closely watched ElastiCache evolve over the years, I am delighted to see ElastiCache being used by thousands of customers – including the likes of Airbnb, Hulu, McDonalds, Adobe, Expedia, Hudl, Grab, Duolingo, PBS, HERE, and Ubisoft. ElastiCache for Redis delivers predictable microsecond latencies and is super easy to use. Our customers are using ElastiCache for Redis in their most demanding applications, supporting millions of users. Whether it is gaming, adtech, travel, or retail—speed wins, it's simple.
As the use cases for Redis continue to grow, customers have demanded more flexibility in scaling their workloads dynamically, while continuing to be highly available and serving incoming traffic. To give you some examples, I've been talking to a few gaming companies lately, and their conversations are about the need for speed and flexibility in scaling, both in and out. They deal with high variability in workloads based on game adoption or seasonality, such as upcoming holidays. If a game leaderboard surges because of a new game title, and tons of players flock to play the game, gaming platforms want to resize the cluster online to handle the bigger load. But as demand decreases, they should just as easily be able to scale-in the environment to optimize costs, all while staying online and serving incoming requests.
Our retail customers have shared similar challenges about managing workload surges and declines driven by big sale events. Some customers have also shared their experiences of trying to self-manage Redis workloads and implement online cluster resizing, for workloads where offline cluster resizing was not an option. While open source Redis comes with primitives to help reshard a cluster, they are inadequate. In addition to the cost of self-management, customers have to deal with failures during cluster resizing. Failures can leave the cluster in an irrecoverable state, potentially causing data loss and extended downtime until the cluster can be fixed manually.
At Amazon, we have always focused on innovating on behalf of the customer. With online cluster resizing, our goal was to design a fully managed experience for cluster resharding, which would support both scale-out and scale-in and retain open source compatibility. It has been an exciting journey—one of thought leadership and innovation—that has enabled us to bring the promise of more elasticity and the flexibility to resize workloads, while retaining availability, consistency, and performance.
Under the hood
In a Redis cluster, the key space is split into slots (16,384 slots) and slots are distributed across shards. When a cluster is resharded, these slots need to be redistributed. Apps using Redis are able to pick this up, as Redis clients can auto-discover and keep up-to-date with changes in slot assignment. However, the slots must be moved manually on the server side. Cluster resizing is a complex problem as it involves changing the number of shards and migrating data, while serving read and write requests on the same dataset. A resharding operation to scale out involves adding shards, creating a plan for redistributing slots, migrating the slots, and finally transferring slot ownership across shards, after the slots are migrated.
Atomic slot migration
Online cluster resizing in ElastiCache uses atomic slot migration instead of the atomic key migration that open source Redis comes with. When a key is migrated to the target shard, ElastiCache maintains a copy of the key at the source shard, which retains ownership of the key until the entire slot and all its keys are migrated. This has several benefits:
- Because all the keys in the slot continue to be owned by the source shard, the dataset is never in a slot-split situation. This makes it easy to support operations such as multi-key commands, transactions, and LUA scripts, thereby providing full API coverage while cluster resharding is in progress.
- While slot migration is in progress, the source shard continues to support requests related to keys that have been migrated. This minimizes the time window requiring client redirection, improving latency during migration operation.
- Key ownership stays with the source shard, so replicas in the source shard have up-to-date information on the keys. If there is a failover, the replicas can continue serving commands with the latest key status and there is no data loss.
- The system is more robust. Any errors such as target out of memory, which may halt migration, are easy to recover from, because the source shard has full ownership of the key.
We have also made other enhancements along the way. One important addition is the use of multi-threaded operations at the source shard. Slot migration at the source shard is executed in parallel as a separate thread from the main I/O thread. As a result, key migration no longer blocks I/O on the source, ensuring no availability impact. Additionally, to maintain data consistency, all data mutations during the migration operation are asynchronously replicated to the target shard.
Online cluster resizing is a fantastic addition for our ElastiCache for Redis customers. You can resize your ElastiCache for Redis 3.2.10 cluster to scale- out or scale in, without any application side changes. For more information about getting started with clustered Redis and trying to reshard a cluster, see Online Cluster Resizing.
Many of our customers share my excitement:
Duolingo is the free, science-based, language education platform that has organically become the most popular way to learn languages online. With over 200 million users and seven billion language exercises completed each month, the company's mission is to make education free, fun, and accessible to all. "Amazon ElastiCache has played an absolutely critical part in our infrastructure from the beginning," said Max Blaze, Staff Operations Engineer at Duolingo. "As we have grown, we have pushed the limits of what is possible with single-shard clusters. ElastiCache for Redis online resharding will allow us to easily scale our Redis clusters horizontally as we grow, greatly simplifying the management of our many Redis clusters, empowering us to scale quickly while also reducing cost across our caching layers, and continue to grow with minimal changes to our current services.
Dream11 , India's #1 fantasy sports platform with a growing user base, has over 14 million users in South Asia. "We have been using ElastiCache for Redis with sharded configuration since its launch last year, supporting over 14 million users playing fantasy games of cricket, football, and kabaddi. With peak demand of 1.5 million requests per minute and workloads surging by 10X quickly, our platform requires scaling on-demand and without downtime. This feature enables us to scale-in and scale-out our platform to support the fluctuating game demand, and not having to over provision," said Abhishek Ravi, CIO.
"At SocialCode , our data and intelligence allow Fortune 500 marketers to know and connect with their customers by harnessing the most important digital media platforms -- like Facebook, Instagram, Twitter, Pinterest, Snapchat, and YouTube." Using the new online resharding feature of ElastiCache for Redis will allow us to scale out our ever-growing Audience Intelligence product as we continue to on-board brand data. The ability to perform these scaling operations without downtime is priceless!"
For the What's New announcement, see Amazon ElastiCache for Redis introduces dynamic addition and removal of shards while continuing to serve workloads.

Today marks the 10 year anniversary of Amazon's Dynamo whitepaper, a milestone that made me reflect on how much innovation has occurred in the area of databases over the last decade and a good reminder on why taking a customer obsessed approach to solving hard problems can have lasting impact beyond your original expectations.
It all started in 2004 when Amazon was running Oracle's enterprise edition with clustering and replication. We had an advanced team of database administrators and access to top experts within Oracle. We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded.
Our straining database infrastructure on Oracle led us to evaluate if we could develop a purpose-built database that would support our business needs for the long term. We prioritized focusing on requirements that would support high-scale, mission-critical services like Amazon's shopping cart, and questioned assumptions traditionally held by relational databases such as the requirement for strong consistency. Our goal was to build a database that would have the unbounded scalability, consistent performance and the high availability to support the needs of our rapidly growing business.
A deep dive on how we were using our existing databases revealed that they were frequently not used for their relational capabilities. About 70 percent of operations were of the key-value kind, where only a primary key was used and a single row would be returned. About 20 percent would return a set of rows, but still operate on only a single table.
With these requirements in mind, and a willingness to question the status quo, a small group of distributed systems experts came together and designed a horizontally scalable distributed database that would scale out for both reads and writes to meet the long-term needs of our business. This was the genesis of the Amazon Dynamo database.
The success of our early results with the Dynamo database encouraged us to write Amazon's Dynamo whitepaper and share it at the 2007 ACM Symposium on Operating Systems Principles (SOSP conference), so that others in the industry could benefit. The Dynamo paper was well-received and served as a catalyst to create the category of distributed database technologies commonly known today as "NoSQL."
Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing. As we began growing the AWS business, we realized that external customers might find our Dynamo database just as useful as we found it within Amazon.com. So, we set out to build a fully hosted AWS database service based upon the original Dynamo design.
The requirements for a fully hosted cloud database service needed to be at an even higher bar than what we had set for our Amazon internal system. The cloud-hosted version would need to be:
- Scalable – The service would need to support hundreds of thousands, or even millions of AWS customers, each supporting their own internet-scale applications.
- Secure – The service would have to store critical data for external AWS customers which would require an even higher bar for access control and security.
- Durable and Highly-Available – The service would have to be extremely resilient to failure so that all AWS customers could trust it for their mission-critical workloads as well.
- Performant – The service would need to be able to maintain consistent performance in the face of diverse customer workloads.
- Manageable – The service would need to be easy to manage and operate. This was perhaps the most important requirement if we wanted a broad set of users to adopt the service.
With these goals in mind, In January, 2012 we launched Amazon DynamoDB, our cloud-based NoSQL database service designed from the ground up to support extreme scale, with the security, availability, performance and manageability needed to run mission-critical workloads.
Today, DynamoDB powers the next wave of high-performance, internet-scale applications that would overburden traditional relational databases. Many of the world's largest internet-scale businesses such as Lyft, Tinder and Redfin as well as enterprises such as Comcast, Under Armour, BMW, Nordstrom and Toyota depend on DynamoDB's scale and performance to support their mission-critical workloads.
DynamoDB is used by Lyft to store GPS locations for all their rides, Tinder to store millions of user profiles and make billions of matches, Redfin to scale to millions of users and manage data for hundreds of millions of properties, Comcast to power their XFINITY X1 video service running on more than 20 million devices, BMW to run its car-as-a-sensor service that can scale up and down by two orders of magnitude within 24 hours, Nordstrom for their recommendations engine reducing processing time from 20 minutes to a few seconds, Under Armour to support its connected fitness community of 200 million users, Toyota Racing to make real time decisions on pit-stops, tire changes, and race strategy, and another 100,000+ AWS customers for a wide variety of high-scale, high-performance use cases.
With all the real-world customer use, DynamoDB has proven itself on those original design dimensions:
- Scalable – DynamoDB supports customers with single tables that serve millions of requests per second, store hundreds of terabytes, or contain over 1 trillion items of data. In support of Amazon Prime Day 2017, the biggest day in Amazon retail history, DynamoDB served over 12.9 million requests per second. DynamoDB operates in all AWS regions (16 geographic regions now with announced plans for six more Regions in Bahrain, China, France, Hong Kong, Sweden), so you can have a scalable database in the geographic region you need.
- Secure – DynamoDB provides fine-grained access control at the table, item, and attribute level, integrated with AWS Identity and Access Management. VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Integration with AWS CloudWatch, AWS CloudTrail, and AWS Config enables support for monitoring, audit, and configuration management. SOC, PCI, ISO, FedRAMP, HIPAA BAA, and DoD Impact Level 4 certifications allows customers to meet a wide range of compliance standards.
- Durable and Highly-Available – DynamoDB maintains data durability and 99.99 percent availability in the event of a server, a rack of servers, or an Availability Zone failure. DynamoDB automatically re-distributes your data to healthy servers to ensure there are always multiple replicas of your data without you needing to intervene.
- Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases. In addition, DynamoDB Accelerator (DAX) a fully managed, highly available, in-memory cache further speeds up DynamoDB response times from milliseconds to microseconds and can continue to do so at millions of requests per second.
- Manageable – DynamoDB eliminates the need for manual capacity planning, provisioning, monitoring of servers, software upgrades, applying security patches, scaling infrastructure, monitoring, performance tuning, replication across distributed datacenters for high availability, and replication across new nodes for data durability. All of this is done for you automatically and with zero downtime so that you can focus on your customers, your applications, and your business.
- Adaptive Capacity –DynamoDB intelligently adapts to your table's unique storage needs, by scaling your table storage up by horizontally partitioning them across many servers, or down with Time To Live (TTL) that deletes items that you marked to expire. DynamoDB provides Auto Scaling, which automatically adapts your table throughput up or down in response to actual traffic to your tables and indexes. Auto Scaling is on by default for all new tables and indexes.
Ten years ago, we never would have imagined the lasting impact our efforts on Dynamo would have. What started out as an exercise in solving our own needs in a customer obsessed way, turned into a catalyst for a broader industry movement towards non-relational databases, and ultimately, an enabler for a new class of internet-scale applications.
As we say at AWS, It is still Day One for DynamoDB. We believe we are in the midst of a transformative period for databases, and the adoption of purpose-built databases like DynamoDB is only getting started. We expect that the next ten years will see even more innovation in databases than the last ten. I know the team is working on some exciting new things for DynamoDB – I can't wait to share them with you over the upcoming months.

Today, I am excited to announce plans for Amazon Web Services (AWS) to bring an infrastructure Region to the Middle East! This move is another milestone in our global expansion and mission to bring flexible, scalable, and secure cloud computing infrastructure to organizations around the world. Based in Bahrain, this will be the first Region for AWS in the Middle East. The Region will be in the heart of Gulf Cooperation Council (GCC) countries, and we're aiming to have it ready by early 2019. This Region will consist of three Availability Zones at launch, and it will provide even lower latency to users across the Middle East.
This news marks the 22nd AWS Region we have announced globally. We already have 44 Availability Zones across 16 geographic Regions that customers can use today. We still have another five AWS Regions (and 14 Availability Zones) in China, France, Hong Kong, and Sweden. Plus another AWS GovCloud (US) Region in the United States is coming online by the end of 2018.
I'm also excited to announce today that we are launching an AWS Edge Network Location in the United Arab Emirates (UAE) in the first quarter of 2018. This will bring Amazon CloudFront, Amazon Route 53, AWS Shield, and AWS WAF to the region and add to the 84 points of presence AWS has around the world. Despite this rapid growth, we don't plan to slow down or stop there: we will bring infrastructure everywhere needed to meet our customers' expectations.
2017 continues a busy year for AWS in the Middle East. Back in January we opened offices in the region to serve our rapidly growing customer base. We now have a presence in Dubai, UAE and Manama, Bahrain with teams of account managers, solutions architects, partner managers, professional services consultants, support staff, and various other functions, so that customers can directly engage with AWS. For the new AWS infrastructure Region we will also be hiring datacenter engineers, support engineers, engineering operations managers, security specialists, and many more. We are continually hiring in the Middle East, so those people looking to join our dynamic and rapidly growing team should visit www.amazon.jobs.
In addition to infrastructure, offices, and jobs another investment AWS is making for its customers in the Middle East, and around the world is to run our business in the most environmentally friendly way. One of the important criteria in launching this AWS Region is the opportunity to power it with renewable energy. We chose Bahrain in part due to the country's focus on executing renewable energy goals and its readiness to construct a new solar power facility to meet our power needs. I'm pleased to announce that the Bahrain Energy and Water Authority (EWA) will construct a solar farm that will supply renewable energy to power this infrastructure Region. EWA expects to bring the 100 MW solar farm online in 2019, making it the country's first utility-scale renewable energy project.
You might not know that AWS has a long history of working with customers in the Middle East. We have been supporting the growth of organizations in this part of the world since the early days of our business. We have supported the development of technology skills across the region with Training and Certification programs to help customers develop skills to design, deploy, and operate their infrastructure and applications on the AWS Cloud. We run a range of programs to give people cloud skills, from AWSome Days – a one-day workshop-based training for technical professionals - to online resources such as webinars, whitepapers, articles, and tutorials that help to educate people about AWS.
In the education sector we have been supporting the development of technology and cloud skills amongst tertiary institutes in the Middle East through the AWS Educate program. This provides students and educators with the resources needed to accelerate cloud-related learning. AWS Educate is already available for students attending institutes such as King Abdullah University of Science and Technology in Saudi Arabia, the Higher Colleges of Technology in UAE, Bahrain Polytechnic, University of Bahrain, as well as Oman College of Management and Technology, the Jordan University of Science and Technology, and many others across the region.
For those not in tertiary education, but looking to launch their own business in the Middle East, we have AWS Activate. This gives startups access to guidance and 1:1 time with AWS experts, as well as web-based training, self-paced labs, customer support, third-party offers, and up to $100,000 USD in AWS service credits. We also work with a number of incubators and accelerators in the region. In Saudi Arabia AWS works with the Badir Program for Technology Incubators and Accelerators at King Abdulaziz City for Science and Technology (KACST). Working with Badir, AWS is providing startups access to technology resources as well as expert advice to help Saudi youth entrepreneurship and to grow new businesses in the Kingdom. We also work with AstroLabs in the UAE and the Cloud 10 Scalerator in Bahrain, as well as a number of international startup accelerator and incubator organizations active in the region, such as 500 Startups, Startupbootcamp, and Techstars. For more details on AWS Activate visit https://aws.amazon.com/activate/.
Through supporting new and existing businesses across the Middle East, organizations of all sizes – in UAE, Saudi Arabia, Kuwait, Jordan, Egypt, Bahrain, and other countries – have been increasingly moving their mission-critical applications to AWS. Some of the Middle East's most established enterprises, such as Actel, Al Tayer Group, Batelco, flydubai, Hassan Allam, Middle East Broadcasting Center, Silah Gulf, Souq.com, Union Insurance, United Arab Shipping Company, and many others, are using AWS to drive cost savings, accelerate innovation, and speed time-to-market.
One story from the Middle East I particularly like is flydubai, the leading low-cost airline in the region. flydubai chose to build their online check-in platform on AWS and went from design to production in four months. It is now being used by thousands of passengers a day. They have also reduced the lead time for new infrastructure services from up to 10 weeks to a matter of hours. Given the seasonal fluctuations in demand for flights, flydubai also needs IT infrastructure that allows it to cope with spikes in demand, making this a great use case for cloud.
AWS also works with a number of government organizations across the Middle East. The Bahrain Ministry of Education, the Ministry of Justice, and the Bahrain Institute of Public Administration (BIPA) are moving workloads to AWS. The BIPA has moved their Learning Management System to AWS, reducing costs by over 90%. Another government organization using AWS to reduce costs and increase agility is the Bahrain Information & eGovernment Authority (iGA). The iGA is the government department in charge of moving all government services online and is also responsible for ICT governance and procurement for the Bahrain government. Earlier this year the iGA launched a cloud first policy, requiring new government workloads evaluate cloud-based services first. Through adopting a cloud first policy, they have helped to reduce the government procurement process for new technology from months to less than two weeks. They are also migrating 700 government websites, with more than 50 TB of data, onto AWS, helping them to meet their goal of decommissioning their hosting platform by the end of 2017.
In addition to enterprises and government institutions, startups in the region are also choosing AWS as the foundation for their business and to scale rapidly and expand their geographic reach in minutes. These startups include Alpha Apps, Blu Loyalty, Cequens, DevFactory, Dubizzle, Fetchr, Genie9, Mawdoo3.com, Namshi, OneGCC, Opensooq.com, Payfort, Tajawal, and Ubuy, as well as Middle Eastern Unicorn, Careem. Careem runs totally on AWS and over the past five years has grown 10 times in size every year. Another cool startup that comes from the Middle East is Anghami. Anghami is a music service that uses AWS to add over 10,000 tracks a day to its catalogue using Amazon S3. Anghami serves over 750 million monthly streams. Having only been founded in 2012, Anghami has grown rapidly and now has over 50 million users, and offers instant access to over 26 million songs, making it the number one music platform in the Middle East and North Africa (MENA) region.
Alongside customers, we also work with a vibrant partner ecosystem across the Middle East, including AWS Partner Network (APN) Partners that have built cloud practices and innovative technology solutions on AWS. AWS APN Consulting and Technology Partners in the Middle East that are helping customers to migrate to the cloud include Al Moayyed Computers, Batelco, C5, du, DXC Technology, Falcon 9, Infonas, Integra Technologies, ITQAN Cloud, Human Technologies, Kaar Technologies, Navlink, Redington, Zain, and many others. As we head toward the opening of the AWS Middle East Region we look forward to working with many more partners.
Despite being active in the Middle East for many years, and the rapid growth we have seen, it is still Day One for us at AWS. We are excited to see the new applications, businesses, and entire industries that will grow in the Middle East in the coming years thanks to the cloud. We also look forward to working with customers from startups to enterprise, public to private sector, and many more as we grow our business in the Middle East and around the world. For more information on our activities in the Middle East, including webinars, meetups, customer case studies, and more, please visit the AWS Middle East page at https://aws.amazon.com/aws-me/.


